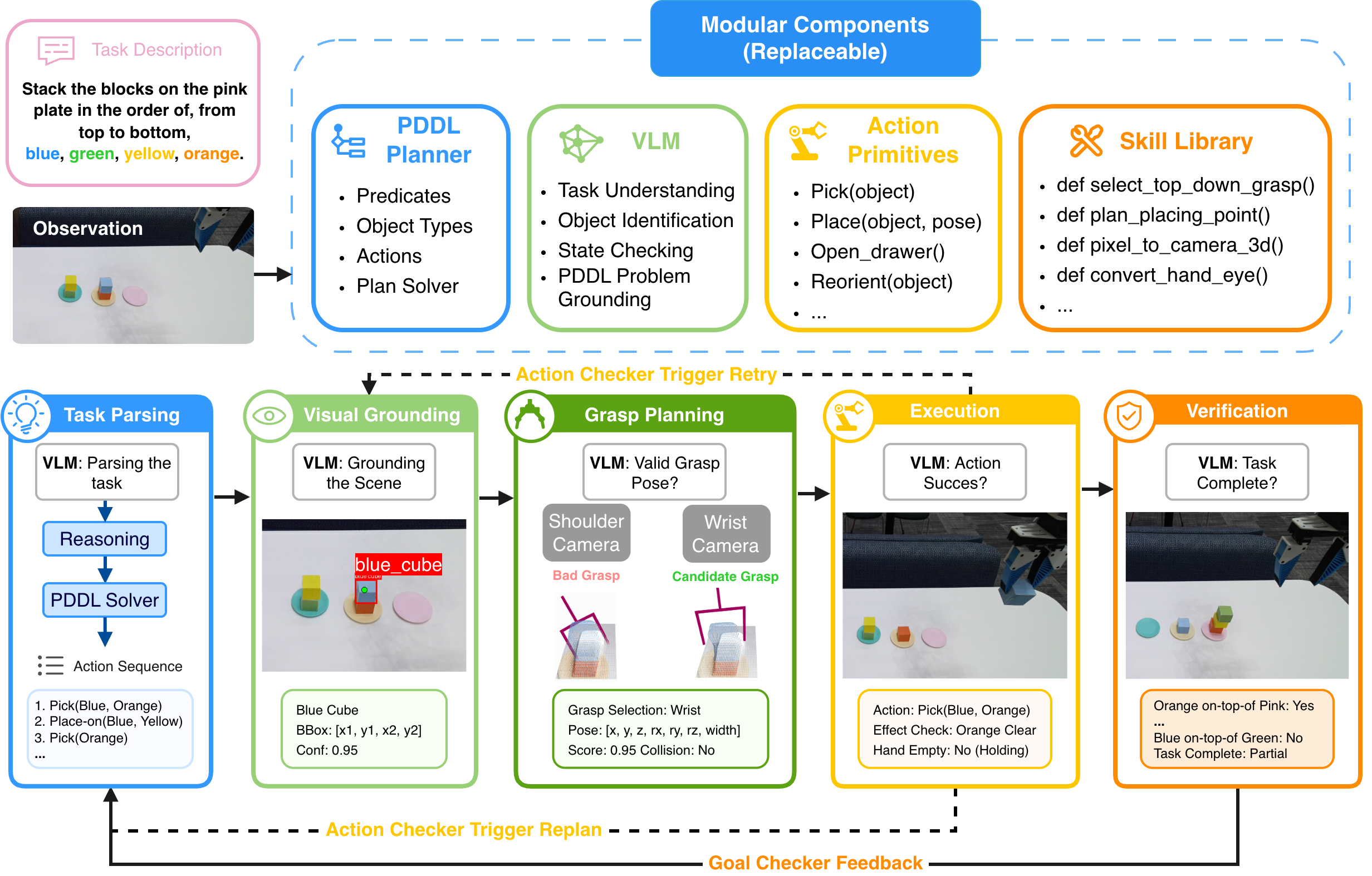
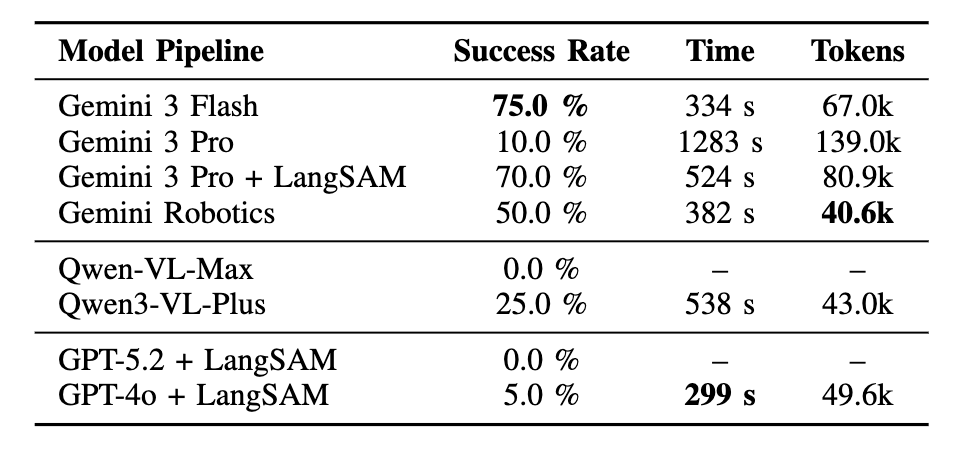
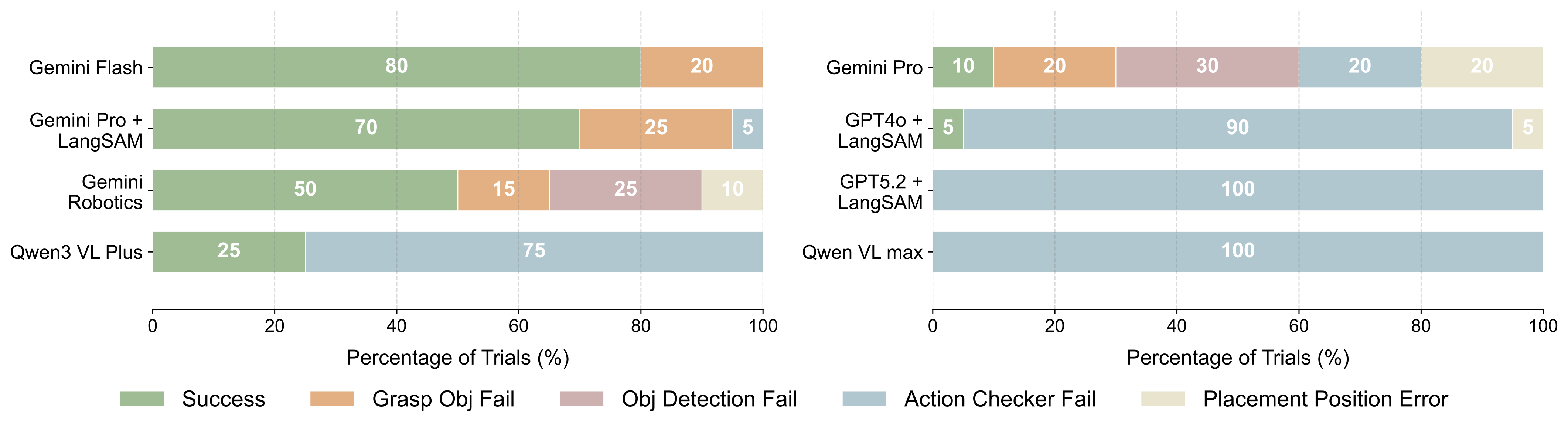
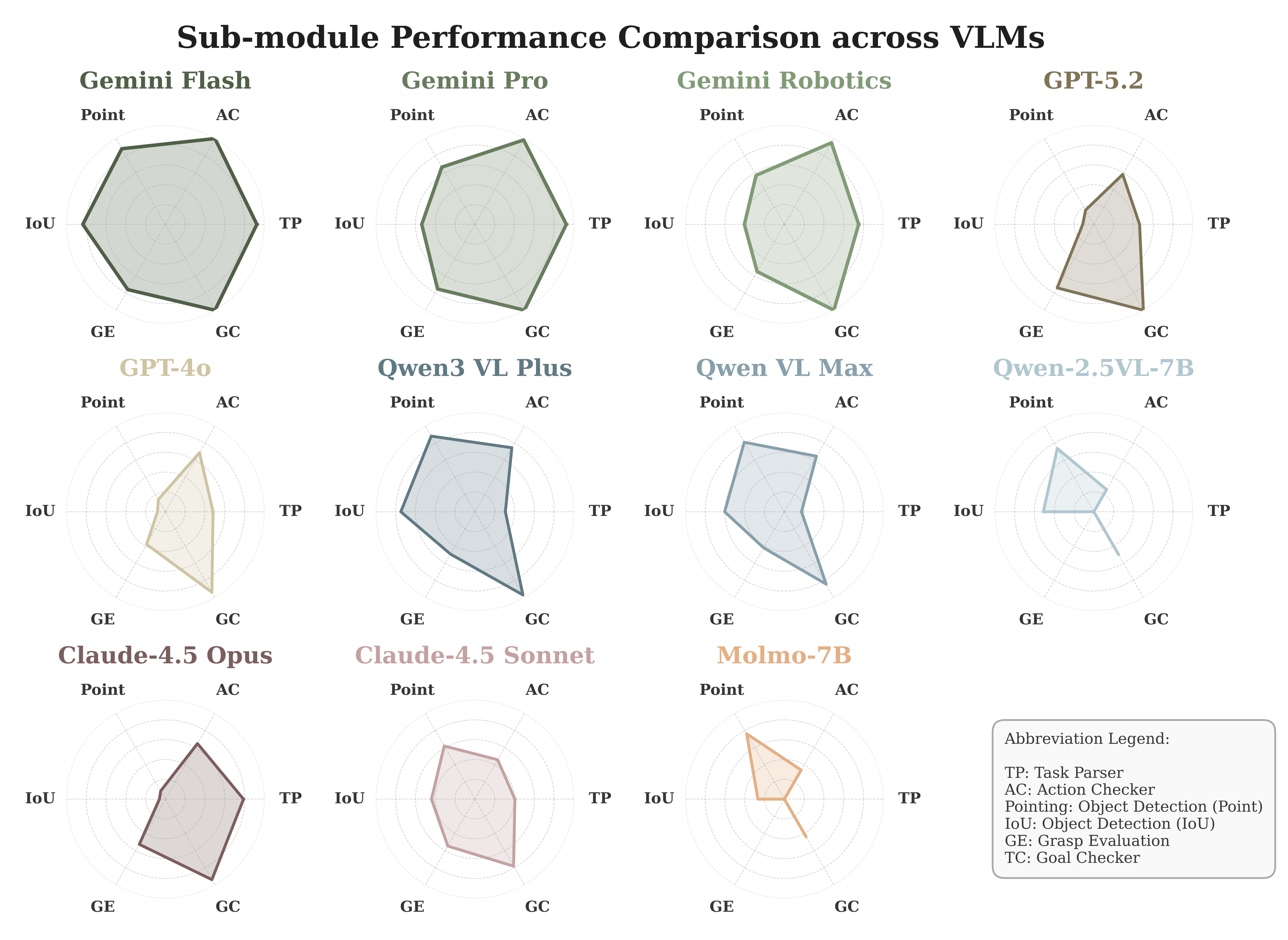
PLanAR: Planning-Language-Grounded
Agentic Reasoning for Robot Manipulation
1Purdue University
2Instituto Italiano di Tecnologia
*Equal contribution
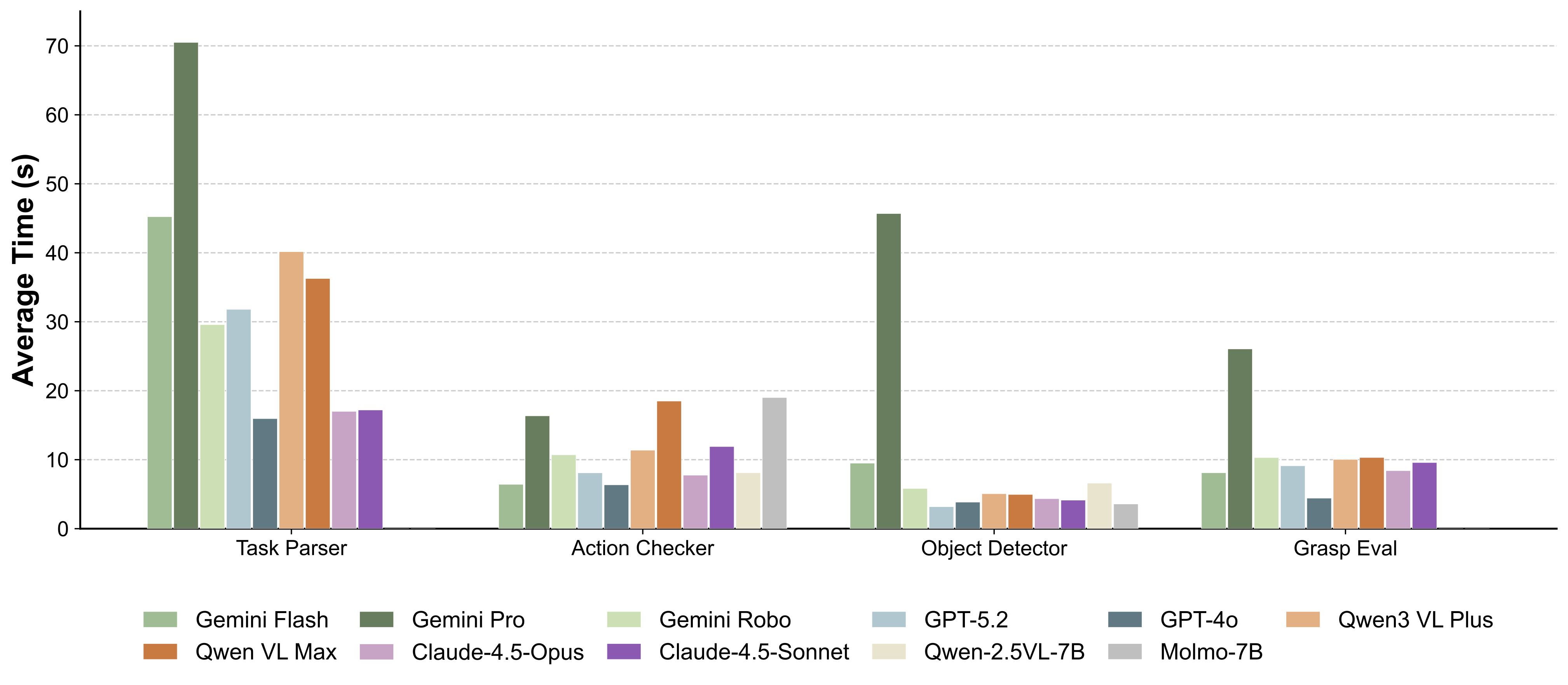
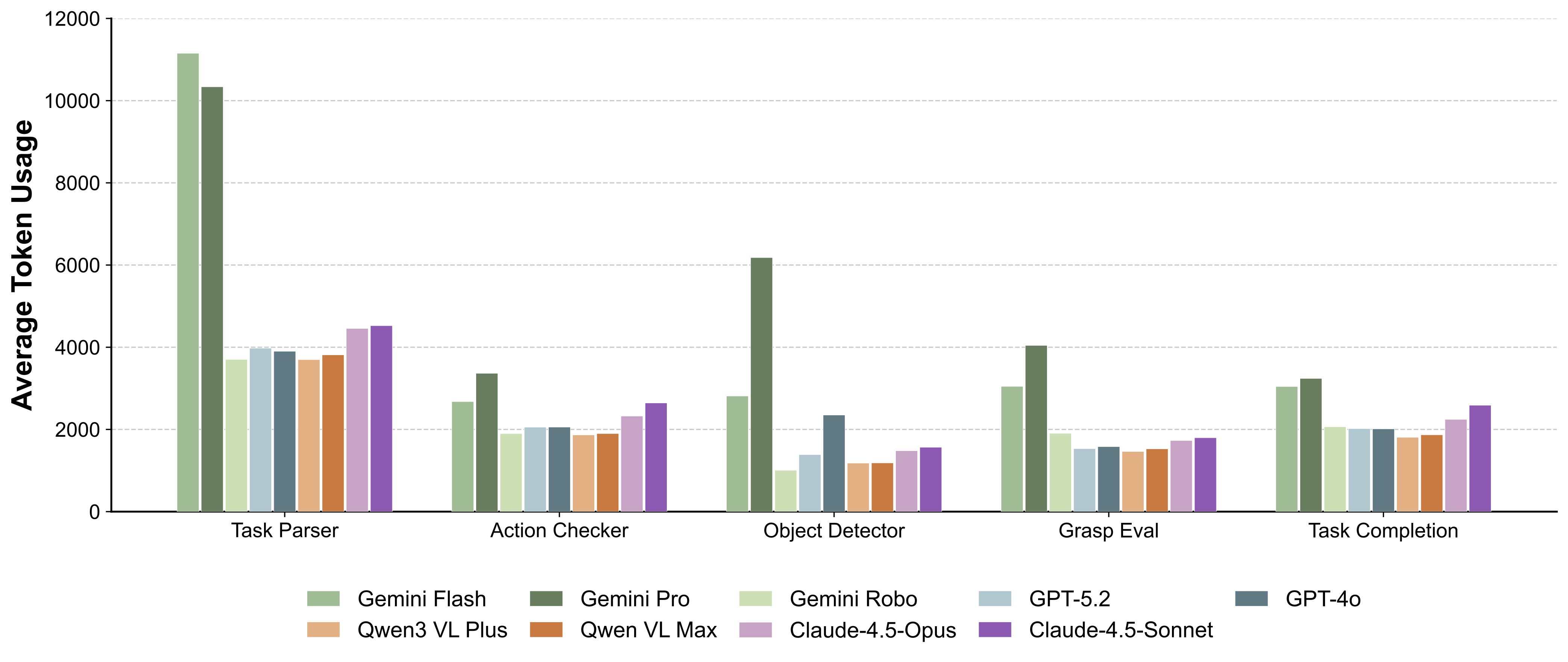
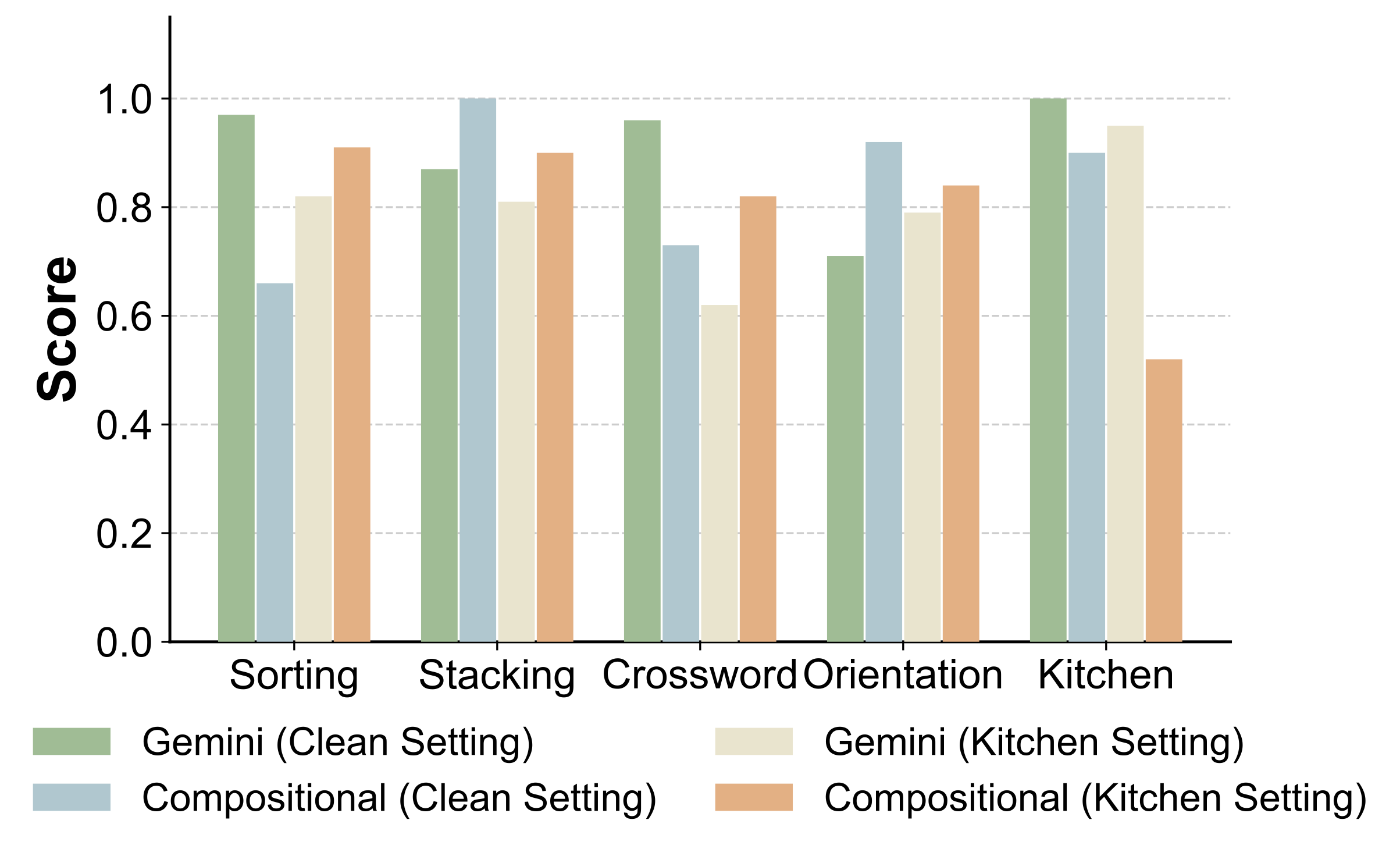
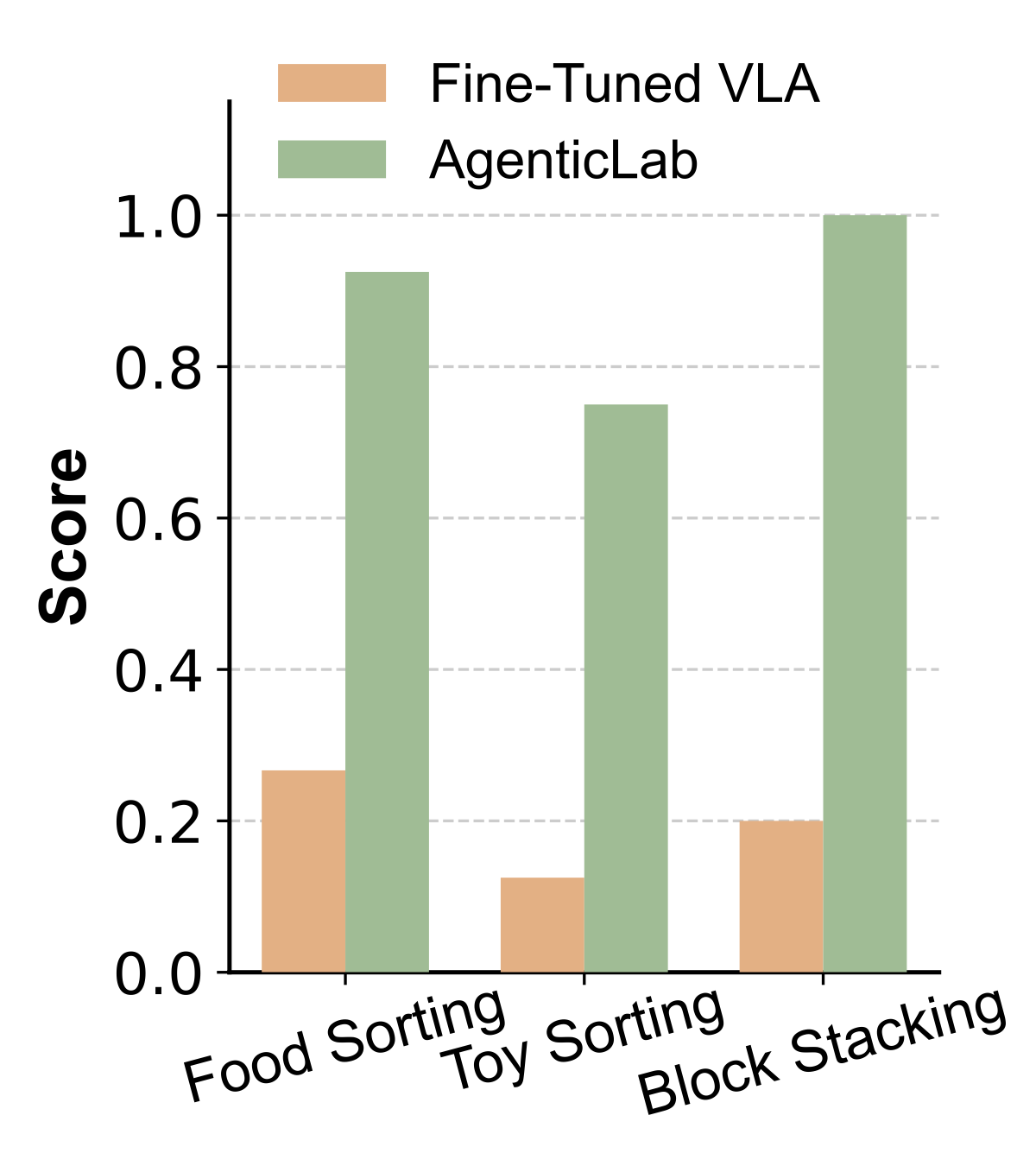
 The full hardware–software stack of PLanAR will be released.
The full hardware–software stack of PLanAR will be released.